Data Ownership / 資料所有權

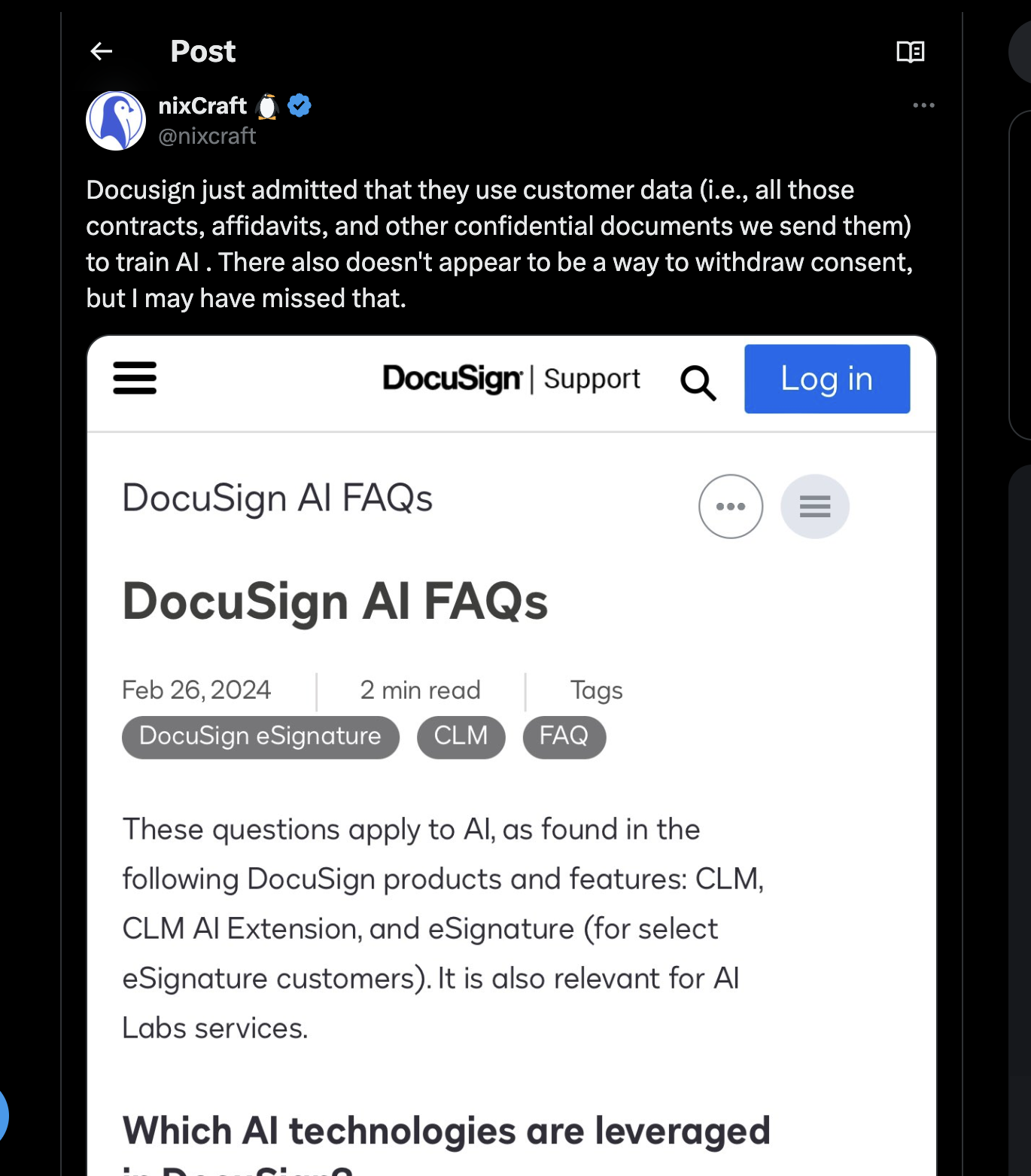
網際網路平臺對個人資料的使用問題由來已久。大科技公司以“個性化”體驗為由,捕獲、重複使用並出售使用者資料,試圖讓廣告和推送內容與使用者興趣更匹配。然而,這種行為常常讓使用者感到被侵入隱私,尤其當平臺不僅捕獲點選資料,還開始記錄與 AI 的互動時,關於資料歸屬的問題變得更加複雜。
生成式 AI 的發展使得個人資料的界限更加模糊:
- 什麼屬於使用者?
- 什麼屬於平臺?
- 生成內容中難以界定的資料如何處理?
在市場規範和原則尚未完全清晰的情況下,許多 AI 公司採用了 資料保留模式(Data Retention Pattern),為使用者提供一定程度的選擇。
功能細節與變體
資料共享選項通常以**開關選項(toggle)**形式出現在使用者或企業設定中,附帶簡短說明,解釋公司使用使用者資料改進模型的必要性。這些介面的設計趨於一致,但具體互動原則有所差異。
- 預設設定:選擇加入(Opt-in)或退出(Opt-out)
預設開啟(Opt-in)
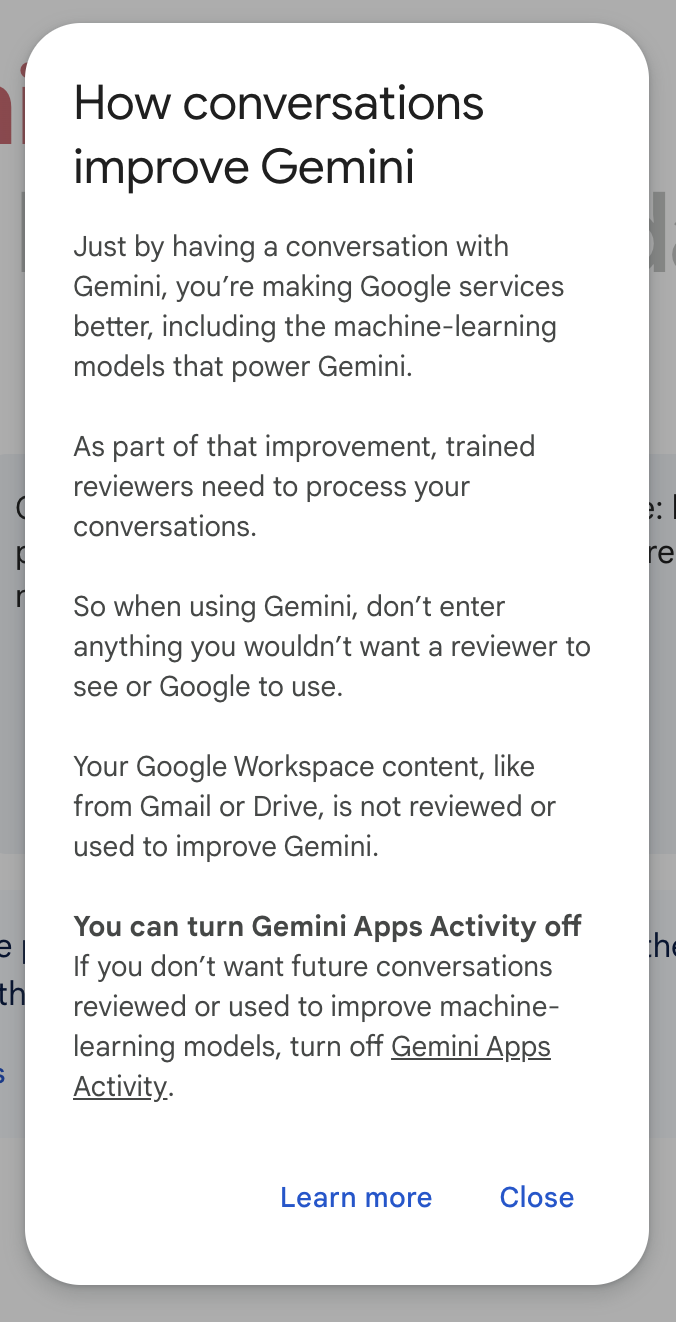
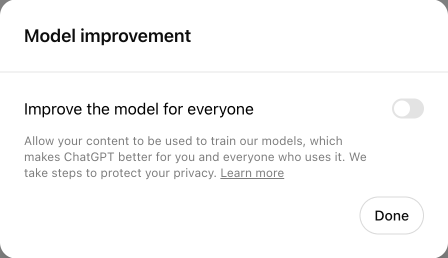
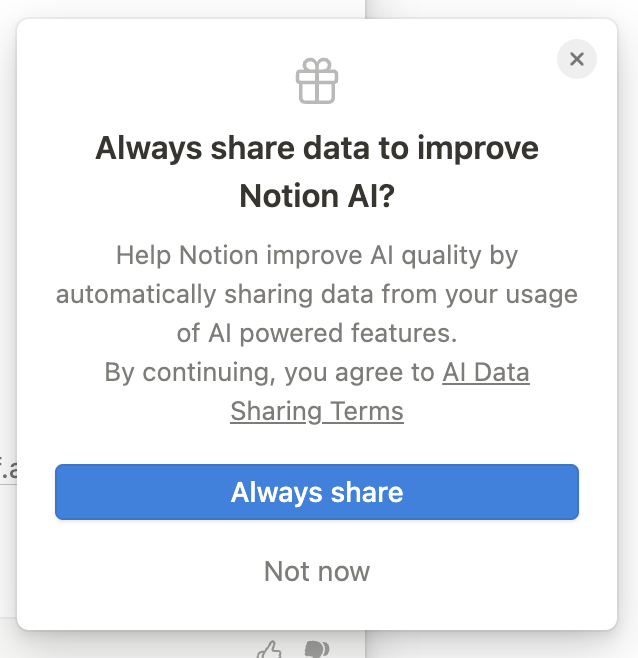
大多數平臺如 ChatGPT、Substack 和 Github,預設將資料共享設定為開啟狀態。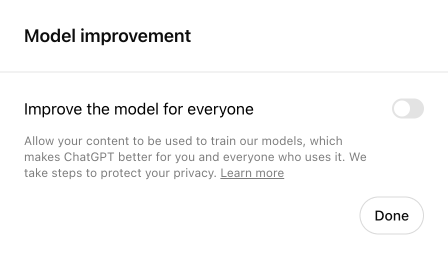
預設關閉(Opt-out)
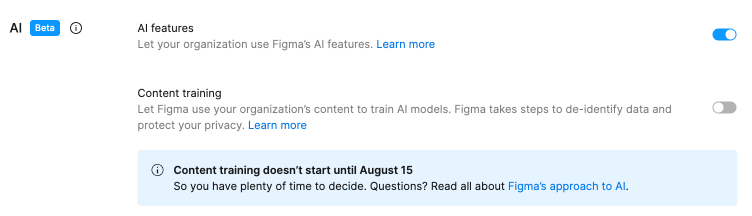
2024 年 Figma 在釋出 AI 功能時,預設將資料共享關閉,體現了使用者優先的設計理念。
- 付費與免費使用者的區別
許多平臺僅對付費使用者提供資料共享開關,免費使用者預設共享資料。
商業邏輯:AI 的執行成本高昂,免費使用者透過資料貢獻“付費”。
趨勢:隨著相關法律逐步完善,預計這一模式將受到更大壓力。
- 企業賬戶與個人使用者的差異
在企業級服務中,資料共享設定通常在管理員控制面板中,而非個人使用者設定中。
目的:確保資料使用符合企業安全政策,無需依賴員工的個人操作。
- 完全隱私的解決方案
一些公司如 Limitless.ai 不使用使用者資料訓練模型,並明確寫入隱私政策,禁止第三方合作伙伴利用使用者資料。
設計建議:對這種策略,應在設定介面明確告知使用者,以免誤解為缺少隱私保障。
使用者控制的優勢
- 資料自主權:資料共享選項讓使用者決定何時以及如何分享資料。如果平臺能贏得使用者信任,使用者可能願意將資料貢獻給公共模型。
- 改進基礎模型:AI 公司的基礎模型需要不斷更新以保持相關性。
當使用者發現模型對其有幫助時,他們可能更傾向於貢獻資料,從而幫助模型持續改進。
潛在風險與挑戰
- 規則模糊:使用者對資料濫用的擔憂源於過去十年科技公司對個人資料的侵佔行為。AI 公司有責任清晰透明地解釋資料的使用和儲存規則,避免混淆。
- 使用者信任危機:如果平臺未能妥善處理使用者資料或發生失誤,可能損害使用者信任。例如,資料洩露或模型訓練過程中違規使用資料,都會加劇消費者的不信任。
未來方向與建議
- 增強透明度:在介面中加入額外背景資訊,詳細說明資料共享的影響,讓使用者清楚自己的選擇意味著什麼。使用易理解的語言描述隱私政策,避免過度依賴法律術語。
- 調整預設設定:考慮預設關閉資料共享,以尊重使用者隱私。儘管這可能增加模型改進的難度,但更能贏得使用者信任。
- 企業與個人設定分層管理:為企業級賬戶提供集中控制,確保資料共享符合組織的安全標準。對個人使用者則提供更多個性化選擇,例如劃分不同的資料使用場景。
- 探索完全隱私解決方案:長期來看,不依賴使用者資料的模型將成為新的發展方向。公司可以透過技術創新減少對資料的依賴,同時提供高質量的服務。